
AI十级「找茬」选手,非这个书生莫属,节后开源!

新智元报道
编辑:好困桃子
为了测试,研发团队的大哥都爬树上了!什么模型竟然只需 10% 的训练数据,性能就能超越同行,还会免费开源?
考验你眼力的时候到了!
只看一眼,看出什么了嘛?

一块木地板?
只答对了一半,其实图中还有一只喵。
下一个问题,这是什么品种的猫?啊...这...

承认吧,你是辨别不出来的,但是这个 AI「一眼」就搞定了。
而这么厉害的 AI 还有个诗意的名字,叫「书生」。
更厉害的是,基于「书生」的通用视觉开源平台 OpenGVLab 将会在春节后全部公开!
通用?视觉?
近几年,语言模型的发展可谓是相当迅猛,百花齐放。
小到 3.54 亿参数的 BERT,大到 5300 亿参数的威震天-图灵,以及 1.6 万亿参数的混合模型 Switch Transformer,顺便还有首次常识问答超越人类的 KEAR。
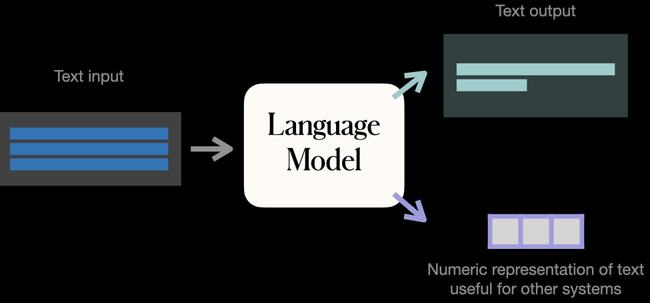
那么,视觉模型这边又如何呢?
目前的 CV 领域主要是图像匹配文本 CLIP 和文本生成图像 DALL·E这种单一模型。
但是 NLP 方向的各种成绩都表明,发展预训练大模型不仅仅能够处理多种复杂任务、适用多种场景和模态,而且能够增加模型的复用率,减少了模型定制化开发的开销进而也降低了成本。
而且,通用模型也是通往通用人工智能的必经之路。

和通用语言模型类似,通用视觉模型的出发点和训练思路也需要事先通过收集海量的无监督数据。然后通过自监督等方式来训练,得到通用的预训练模型。最后根据具体的下游任务再将通用预训练模型迁移到具体任务上去解决具体问题。
不过,从任务角度看,通用视觉模型主要还是解决纯视觉任务,也涉及一些视觉语言相关的多模态任务,而通用语言模型主要在解决语言相关的任务。而从模型训练角度看,两者的模型结构存在一些差异,具体训练的监督形式也不一样。
但是想要实现模型的通用性,很难。
首当其冲的就是,训练数据不够用。

训练一个性能合格的深度学习模型,所需的数据采集量,少则十几万,多则千百万张图片,比如自动驾驶和人脸识别,对于数据的需求,达到十亿级别,但性能仍未饱和。
在现实应用中,AI 需要大量业务数据和用户互联网行为数据的融合,而企业可以应用的数据则非常有限。
数据都采集不到,就更不用提什么「高质量」了。
此外,模型对于数据的学习效率又低,无疑又是雪上加霜。
于是,N个任务就需要开发N个高度定制的模型同时,每个模型在训练的时候又需构建标注数据集进行专项训练,并持续进行权重和参数优化。
时间、人力以及资源的成本直接拉满。

即便如此,依然有人想要挑战一番。
2021 年 11 月,上海人工智能实验室联合商汤科技 SenseTime、香港中文大学、上海交通大学共同发布了新一代通用视觉技术体系——「书生」(INTERN)。

论文地址:https://arxiv.org/abs/2111.08687
通才是如何练成?
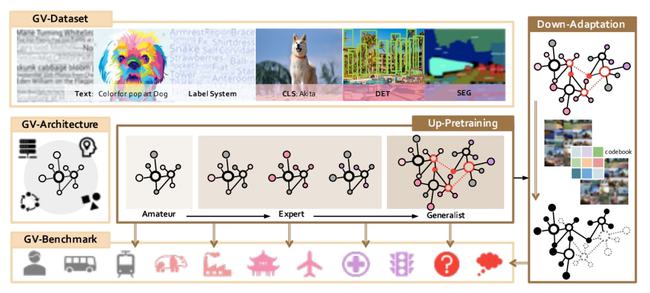
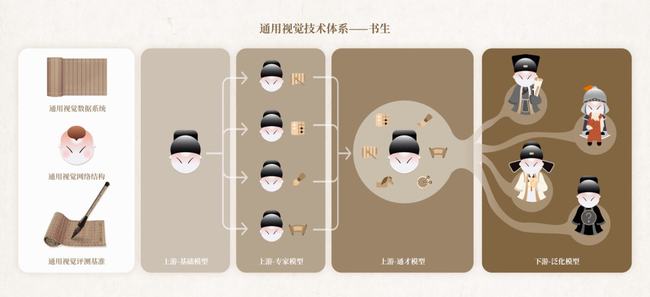
作为通用视觉技术体系的「书生」有三个基础设施模块,分别为:
通用视觉数据系统(GV-Dataset)
通用视觉网络结构(GV-Architecture)
通用视觉评测基准(GV-Benchmark)
这三个基础模块有什么作用?
它们就像「百科全书」、「高楼基底」一样。「书生」通才的道路上学到的海量知识和建模、评测等基础能力就靠这三个基础模块了。

具体点讲,其中,在通用视觉数据系统中包含了大量的高质量数据集:
1. 超大量级精标注数据:除了整合现有开源数据集,还进行了大规模数据图像标注任务,涵盖了图像分类,目标检测以及图像分割等任务,数据总量级达到 40M。
分类任务数据量级为 71M,其中包含 9 个公开数据集 28M,以及自标注数据 43M。目标检测任务数据量级为 4M,其中包含 3 个公开数据集 3M,以及自标注数据 1M。
2. 超大标签体系:总标签量级达到 119K,几乎覆盖了所有现有开源数据集,在此基础上扩充了大量细粒度标签。
极大地丰富了图像任务的标签,提供了更为合理的组织方式,以及可扩展的标签延伸策略。
3. 首次提出视界(realm)概念:结合「书生」标签体系,可以极大提升预训练模型的性能。

在通用视觉网络结构中,MetaNet 是一种自研的模型搜索网络,它最大的变种包含百亿的参数量,是当今最大的视觉网络之一。
这个网络结构结合了视觉卷积和前沿的视觉自关注机制,通过大规模强化学习网络结构搜索算法,取得最佳算子组合,达到模型效率和效用的最大化。
在相同的资源限制的情况下,「书生」的视觉网络获得在不同视觉任务下更优异的精度。
在获得超大规模的视觉神经网络以赋能计算机视觉社区的研究的同时,「书生」的网络支持灵活地进行不同规模的调整,以适应不同程度的工业化落地时的运算能力需求,赋能视觉算法的工业落地。
有了这样的网络结构之后,就可以对其进行了从「基础模型-专家-通才」模型的训练策略,极大地增强这种网络结构的泛化能力。

第三个便是视觉评测基准,它就像是一个「擂台」,收集了 4 种类型共 26 个下游任务。
不仅包括常规分类任务还包括细粒度分类任务,还包括医疗图像等特殊领域的分类任务、行人检测等热门检测任务,扩展到分割与深度任务,可以很好地衡量模型的泛化能力。
这一视觉评测基准还引入了百分比样本(percentage-shot)的设置。
亮点在于,下游任务训练数据被压缩的同时,还可以很好地保留原始数据集的长尾分布等属性。
「书生」除了这三个基础设施模块之外,还有四个训练阶段模块。
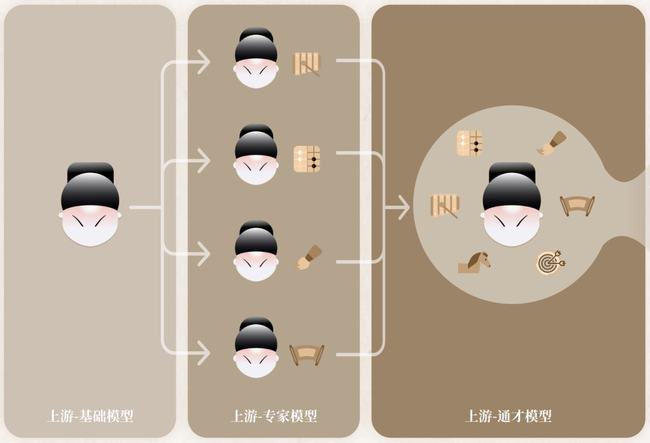
在「书生」(INTERN)的四个训练阶段中,前三个阶段位于该技术链条的上游,在模型的表征通用性上发力。
第一阶段,「基础能力」的培养需要经过一个跨模态的预训练过程,通过大量的图像-文本对进行通用模型的预训练,让其学到广泛的基础常识,为后续学习阶段打好基础;
第二阶段,培养「专家能力」,即多个专家模型各自学习某一领域的专业知识,让每一个专家模型高度掌握该领域技能,成为专家;
第三阶段,培养「通用能力」,此时的通才模型继承了大规模多模态的预训练信息,也融合了多样的感知任务的信息,「书生」在各个技能领域都展现优异水平,并具备快速学会新技能的能力。
通过前三个模块阶梯式的学习,「书生」具备了高度的通用性和良好的泛化能力。
当进化到位于下游的第四阶段时,系统将具备「迁移能力」,此时「书生」学到的通用知识可以应用在某一个特定领域的不同任务中。
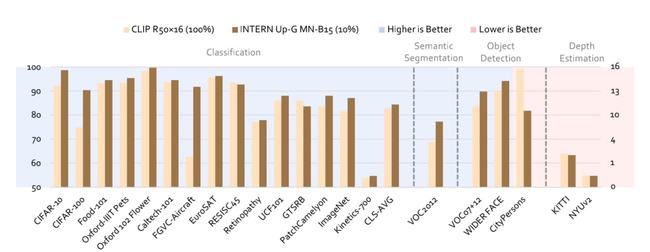
从实验结果来看,相较于当前最强 CV 模型 CLIP,「书生」在准确率和数据使用效率上均取得了大幅提升。
具体来讲,在分类识别、目标检测、语义分割及深度估计四大任务 26 个数据集上,「书生」的平均错误率分别降低了 40.2%、47.3%、34.8% 和 9.4%。

同时,「书生」只需要1/10 的下游数据,就干翻了 CLIP 基于完整下游数据的准确度。

书生不是「书呆子」
光学不去练,不会用,还是没啥本事。
要明确的是,商汤的「书生」可不是一个书呆子。
怎么讲?
首先,它能够举一反三。
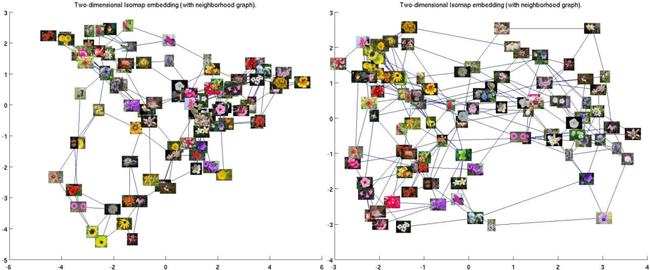
举个形象点的栗子,比如让「书生」识别花的种类,每一类只需要提供 2 个训练样本,识别准确率高达 99.7%。

这个花卉数据集由 102 种英国常见的花组成,每个类别有 40 至 258 张图片。其中包含有很大的比例、姿势和光线变化。
它不仅有触类旁通的能力,而且在自动驾驶、智慧城市、智慧医疗等场景均已经实现了落地应用。
就拿自动驾驶来说吧,要想不成为马路杀手,一套 CV 模型需要能够识别各种物体,包括交通标志,车道线识别等,还得预测出与障碍物的距离,行人检测等等。

对于这些任务,单一视觉模型是无法胜任的。
而「书生」技术体系从数据、模型等各个方面出发,对自动驾驶感知模型,尤其是长尾类别和场景非常友好,在小样本甚至是零样本的应用场景下表现明显优于既往模型。
其实,在实际场景应用中,数据都存在长尾分布的现象,少量类别占据大多数样本,而大量类别仅有少量样本。
在智慧城市中也是同样的道理,面对很多长尾、碎片化场景就不得不祭出通才「书生」了。
生活中,我们经常会见到城市街道上的井盖频频丢失的问题。

如果 CV 模型没有关注城市治理的长尾问题,偷井盖问题很难得到解决。况且,井盖也有很多种样子。
但是,这对于通才「书生」来讲都是小 case。只要每一类提供 2 个训练样本,问题不就搞定了吗。

因为它已经在训练阶段被「喂下」大量数据成为通才,只需要看到少量样本,就具备了举一反三的能力。
有了「书生」的加持,不仅可以预防井盖丢失,还能实现事后追责的精细化管理。

此外,智慧制造、智慧医疗等应用中还会存在很多类似的长尾场景,而通用视觉「书生」的推出能够让业界以更低的成本获得拥有处理多种下游任务能力的 AI 模型。
并以其强大的泛化能力支撑实际场景中大量小数据、零数据等样本缺失的细分和长尾场景需求。

书生(INTERN)技术体系可以让 AI 模型处理多样化的视觉任务
这些暴力计算下的 AI 场景需要强大的算力作为支撑,这时候 SenseCore 商汤 AI 大装置正好就派上用场了。
AI 大装置正是通过超强的算力基础,为人工智能的研发、创新和应用提供源动力。

正如商汤科技研究院院长王晓刚所提到的那样:
「书生」通用视觉技术体系是商汤在通用智能技术发展趋势下前瞻性布局的一次尝试,也是 SenseCore 商汤 AI 大装置背景下的一次新技术路径探索。 「书生」承载了让人工智能参与处理多种复杂任务、适用多种场景和模态、有效进行小数据和非监督学习并最终具备接近人的通用视觉智能的期盼。 希望这套技术体系能够帮助业界更好地探索和应用通用视觉 AI 技术,促进 AI 规模化落地。
不过,想要成为一个优秀的通用视觉模型,「书生」还有三个挑战需要解决:
1. 模型优化速度的提升
对于一个好的预训练模型,往往需要更大更好的网络结构,以及大规模的数据,这就会导致几天甚至几周的模型训练时间,如何在保持表征能力的同时,大幅度加速模型的训练过程,具有非常重大的现实意义。
2. 更大范围内的通用能力仍待探索
书生模型,可以很好地在常见的视觉任务里达到通用的效果。在跨度较大的领域,比如超分等底层视觉任务,书生模型还有很大的进步空间。
3. 大模型到小模型的转变
将大模型的表征能力无损失的迁移到可部署到终端设备上的小模型,对于预训练模型的推广有非常大的价值。
One More Thing
要问这个模型好不好做?
研发急得都直「爬树」!

为了测试模型在 zero-shot 下的精度如何,书生研发团队的模型科学家都亲自上演了「爬树」特别节目。通过创造特殊场景,以随机生成图片,去考验模型能力。
(研究需要,大家请勿模仿^_^)
「书生」看到后,歪嘴一笑。
这不就是「爬树」嘛,置信度 0.96 给你。

而且有趣的是,「书生」模型还注意到了树上人眼都很容易忽略的绳子。
可能,这就是「明察秋毫」吧!

未来,「书生」要做的一件事情:
基于「书生」的通用视觉开源平台 OpenGVLab 也将在今年年初正式开源,产学研一道共创通用 AI 生态!

而即将开源的 OpenGVLab,正是基于「书生」的通用视觉开源平台。
其中的网络结构除了商汤自研的 MetaNet,还包含大家普遍使用的 ResNet, MobileNet, ViT, EfficientNet 等,以满足不同场景的应用,赋能计算机视觉。
然而,「书生」的布局不止于此。
OpenGVLab 将与上海人工智能实验室此前发布的 OpenMMLab、OpenDILab 一道,共同构筑开源体系 OpenXLab,持续推进通用人工智能的技术突破和生态构建。
「书生」研发团队的一位成员调侃道,「随着书生模型精度越来越高,我们的办公楼层越来越高。」

开源的「书生」,前景广阔。